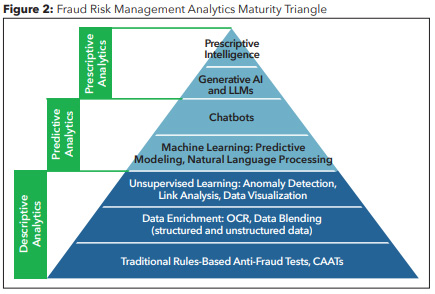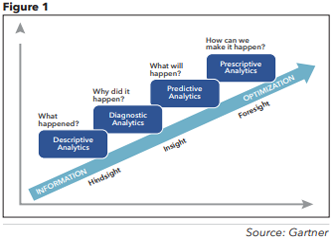
Predictive analytics
Moving up the maturity curve, we have predictive analytics, which is just what it sounds like — it seeks to predict likely outcomes and make educated forecasts based on historical data. In eDiscovery, this technique was all the rage over the past 15 to 20 years when investigators could find a few “hot,” “responsive” or “privileged” emails or documents and use predictive analytics (also known among litigation, investigation and eDiscovery professionals as “technology-assisted review”) to find statistically similar documents. In a previous Innovation Update column, I demonstrated how to use predictive analytics with structured, transactional data to identify high-risk vendor payments during a U.S. Department of Justice investigation. (See “Using technology-assisted review to uncover suspicious transactions,” Fraud Magazine, November/December 2022, tinyurl.com/r3ah4bv5.) Simply put, predictive analytics extends trends into the future to show possible outcomes. This is a more complex version of data analytics because it uses probabilities for predictions instead of interpreting existing facts.
Statistical modeling or machine learning is commonly used with predictive analytics. It might answer investigative questions such as whether your payments data include transactions statistically similar to those you’ve previously determined to be fraudulent. It’s like saying “find me more like this.”
The primary challenge with predictive analytics is that the insights it generates are limited to the data, and in a fraud risk management context, most companies typically don’t have huge amounts of fraudulent transactions to train an effective model. This means that small or incomplete datasets won’t yield predictions as accurate as large datasets might. In another recent Innovation Update column, I described some of my anticorruption research out of MIT showing that when companies collaborate to share information about third-party payments and high-risk, potentially fraudulent transactions, they have a 25% greater chance of predicting improper payments than when each company’s model is run in isolation. [See “From many, comes one (algorithm),” Fraud Magazine, March/April 2023, tinyurl.com/2dap499x.]